Das Leben einer Wochenend-App
Jeder Beitrag in diesem Blog seziert ein Organ der Plattform — die Karte, die Datenbank, den Gefrierschrank. Dieser hier beobachtet den ganzen Organismus, live. Es ist eine wahre Geschichte: eine App, an einem Freitagabend auf der Plattform gebaut, mit den tatsächlichen Prompts, den tatsächlichen Zeitstempeln und der tatsächlichen Rechnung. Nichts in diesem Beitrag ist ein Mock-up — auch nicht der Teil, in dem einem Build das Budget ausgeht, und auch nicht der Teil, in dem der erste Bug von einem Menschen gefunden wird.
Freitag, 18:42 — ein Absatz statt einer Spezifikation
Die komplette Spezifikation, genau so getippt:
Ich fahre im Februar mit 7 Freunden zum Skifahren und habe die Tabelle satt. Ich will eine App, in der jeder aus der Gruppe eine Ausgabe eintragen kann, die er bezahlt hat (Liftpässe, Lebensmittel, Sprit, Abendessen), markieren kann, für wen sie gilt, und jederzeit eine Übersicht „wer wem was schuldet" sieht, damit wir am Ende mit möglichst wenigen Überweisungen abrechnen können. Alles in EUR. Muss gut auf dem Handy laufen, weil wir die Sachen auf der Piste eintragen werden.
Kein Schema, keine Seiten, kein Tech-Stack. Drei Anforderungen verstecken sich im Fließtext, und keine davon ist als Anforderung formuliert: mobile-first („auf der Piste"), geteilte Daten („jeder aus der Gruppe") und ein echter Algorithmus — mit möglichst wenigen Überweisungen abrechnen ist ein Min-Cash-Flow-Problem, kein CRUD-Endpunkt.
18:46 — vier Minuten später kommt der Plan des Architekten zurück. Sechs Features, elf Subtasks:
| # | Feature |
|---|---|
| 0 | App-Gerüst & Navigation — mobile-first, Bottom-Tabs |
| 1 | Trip & Mitglieder — die 8 Freunde, konfigurierbare Namen |
| 2 | Ausgabe hinzufügen — wer hat bezahlt, wofür, Betrag, für wen sie gilt |
| 3 | Ausgaben-Feed & Salden |
| 4 | Abrechnen — minimale Überweisungen, um alle Salden auf null zu bringen |
| 5 | Feinschliff & Verifikation — Demo-Daten seeden, die Mathematik end-to-end testen |
Alle drei impliziten Anforderungen haben es in den Plan geschafft, plus eine, nach der niemand gefragt hat: die Mathematik end-to-end testen. Der Plan ist ein Vertrag, kein Bauchgefühl — jede Subtask deklariert die Dateien, die sie erstellen wird, und die Akzeptanzkriterien, nach denen sie beurteilt wird. Objektiv beurteilt: von Compilern und Probes, niemals vom Modell, das sich selbst benotet.
18:52 — Plan mit einem Wort genehmigt („ja").
18:52:15 — die Infrastruktur kommt vor der ersten Zeile Code
Sechs Sekunden nach der Genehmigung, bevor der Agent irgendetwas geschrieben hat, hat das Projekt: einen eigenen Kubernetes-Namespace mit Quotas, einen eigenen PostgreSQL-Branch (Copy-on-Write, sofort, Scale-to-Zero), das React-+-tRPC-Scaffold und das Datenbankschema aus dem Plan. Provisioning ist deterministischer Plattform-Code, keine Agent-Arbeit — der Agent ist hier die am wenigsten vertrauenswürdige Komponente und bekommt ein möbliertes Zimmer ausgehändigt, keinen Werkzeugkasten neben einem Rechenzentrum.
18:52 → 21:11 — der Build, mit Belegen
Hier ist, was ein Agent tatsächlich mit seinem Budget anstellt, laut dem Tool-Ledger dieses Runs:
| Was | Anteil der Schritte |
|---|---|
| Code schreiben | ~24% |
| Verifizieren — Type-Checks, Live-Contract-Probes, In-Pod-Testläufe, Headless-Browsing | ~27% |
| Kontext lesen | ~29% |
| Plan-Bookkeeping (das zugleich die Verifikation auslöst) | ~15% |
| Direkte SQL-Checks gegen die eigene Datenbank | ~4% |
Auf je zwei Schritte Schreiben kamen zwei Schritte Prüfen. Dieses Verhältnis ist keine Tugend des Agenten — es ist die durch Tooling erzwungene Haltung der Plattform: Eine Subtask gilt erst dann als erledigt, wenn die Verifier-Pipeline das sagt. Drei Momente aus dem Ledger zeigen, was das in der Praxis bedeutet:
Eine abgeschnittene Datei wurde am Gate abgefangen. Der Seed-Daten-Schritt gab einmal eine db/seed.ts mit 176 Zeichen aus — ein Modell-Aussetzer, der als Datei-Write „erfolgreich" gewesen wäre. Das Emission-Gate wies sie als degeneriert ab; der Retry schrieb die echte Datei. Die Aufgabe der Plattform ist sicherzustellen, dass der schlechte Tag eines Modells sich nicht ins Produkt kompiliert.
Eine Subtask ist ehrlich gescheitert. Die Mitgliederverwaltungs-Seite verbrannte drei Schritte, ohne eine ihrer deklarierten Dateien zu schreiben, und das Scope-Gate weigerte sich, sie anzuerkennen: Status failing, Evidenz „completed 3 steps without writing any of its declared files." Kein falsches Grün. Im nächsten Durchgang stieß ein Anti-Spiral-Stups den Agenten bei Schritt 11 aus einer Diagnoseschleife — und die Seite landete: fünf Dateien, Tests grün.
Die Mathematik wurde in SQL geprüft. Der Plan sagte die Abrechnung end-to-end testen, also seedete der Agent acht Mitglieder und ein Dutzend Ausgaben und ließ dann WITH balances AS (...)-Queries direkt gegen seinen Branch laufen, um zu verifizieren, dass der Überweisungsplan jeden Saldo auf null bringt — und patchte anschließend seine eigene Testsuite dort, wo sie widersprach. Die App wird mit dieser Suite ausgeliefert; sie kam testbar zur Welt.
Noch ein ehrlicher Moment: auf halber Strecke durch den Plan lief der erste Run in sein Schritt-Budget. Ein Budget ist ein Sicherungsschalter, kein Versprechen, dass jeder Plan in einen Durchgang passt — also sicherte der Run seine fünf verifizierten Subtasks, committete sie und pausierte um 19:53 und sagte das auch so. Dann wartete er — ohne zu rechnen, ohne abzurechnen, ohne Arbeit vorzutäuschen — 35 Minuten lang, bis um 20:28 ein Mensch zurückkam und „continue" tippte. Der zweite Run nahm die Kette dort auf, wo das Ledger den Stopp festhielt, übersprang alles bereits Verifizierte und erledigte die restlichen sechs. (Er versuchte auch die zuvor gescheiterte Seite erneut — dort passierte die oben beschriebene Anti-Spiral-Rettung.)
21:11 — fertig. Elf von elf Subtasks bestanden. Die Wanduhr sagt 2 Std 19 von der Genehmigung bis zur Fertigstellung, aber eine halbe Stunde davon wartete die Plattform bloß, mitten im Plan eingefroren, darauf, dass ein Mensch vom Abendessen zurückkommt. Die tatsächliche Arbeitszeit des Agenten lag bei etwa 1 Std 45. Der Release-Commit ist an die exakte Log-Position der Datenbank gepinnt (bdc2258 @ LSN 0/21933A8), was nach Trivia klingt, bis man Code und Daten gemeinsam durch die Zeit reisen lassen muss.
Das ist die App, in Produktion, fotografiert von demselben Headless-Chromium, das die Plattform für ihre eigenen Runtime-Checks verwendet:
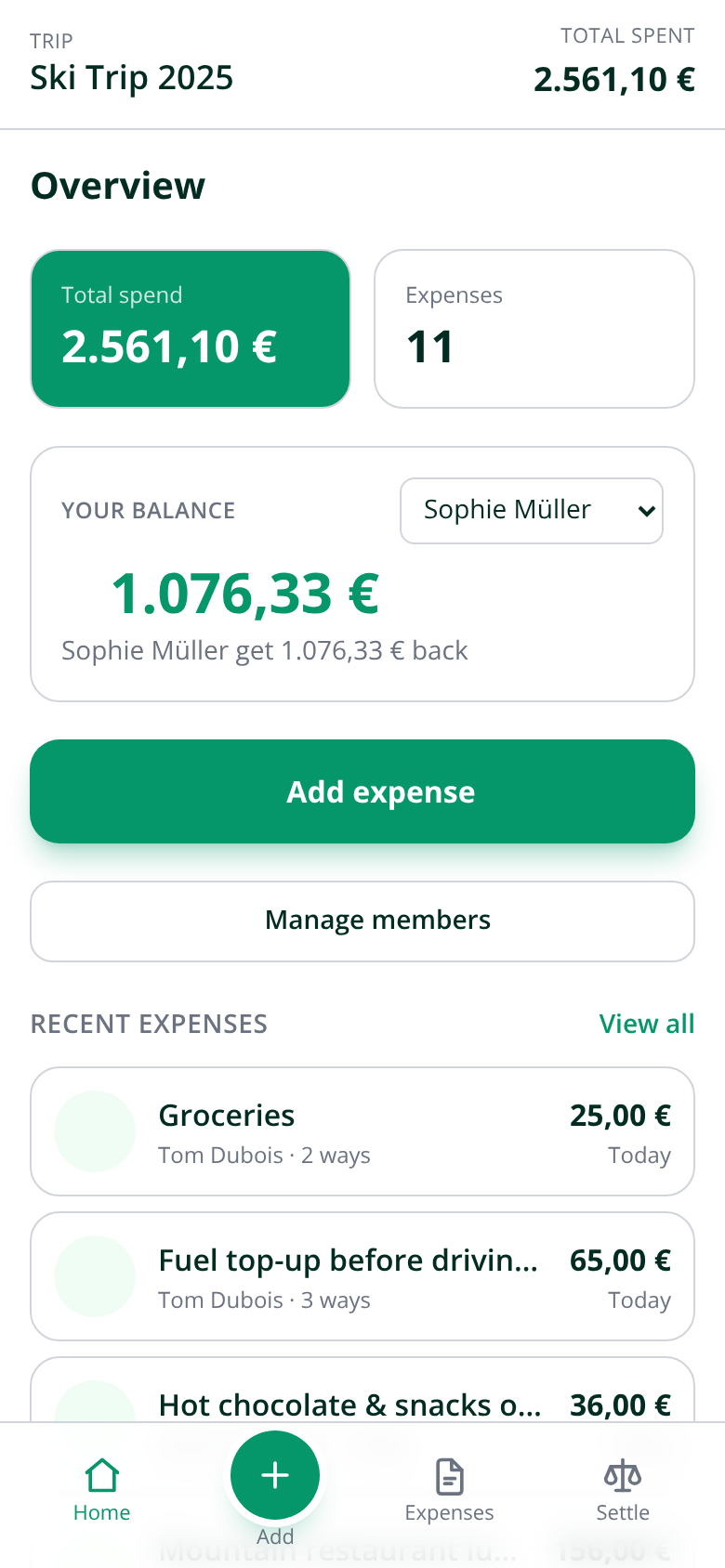
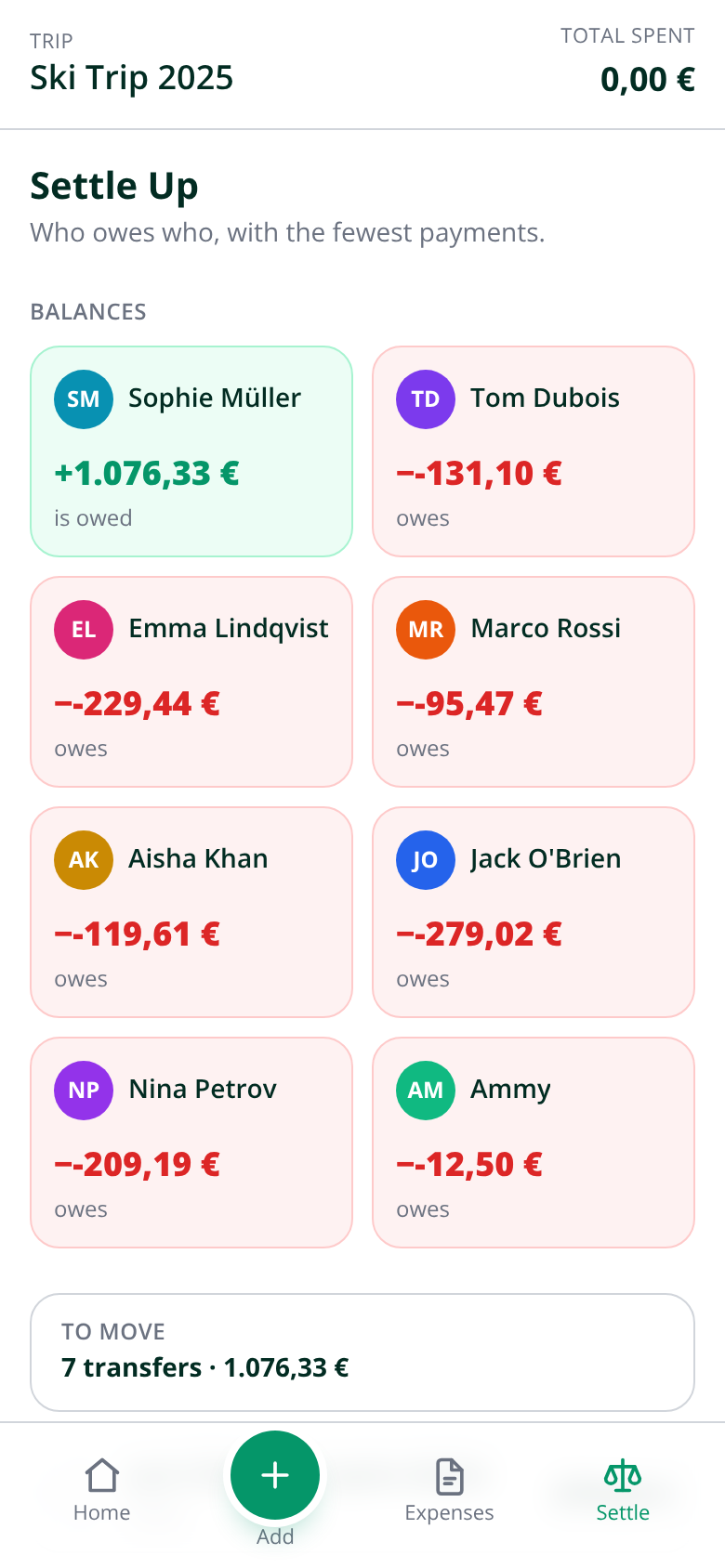
Der Abrechnungs-Screen ist der unterspezifizierte Freitagssatz, ausgeliefert: „wer wem was schuldet… mit möglichst wenigen Überweisungen" wurde zu acht Salden und einem Plan aus 7 Überweisungen — dem Minimum für acht Personen, denn jeder Abrechnungsgraph braucht höchstens n−1 Kanten. Und wenn man bei den negativen Beträgen genau hinsieht, sieht man bereits die nächste Iteration im Bild: ein verdoppeltes Minuszeichen. Der Bug-Report am Dienstag wird ein Satz sein, wie schon der letzte.
21:28 — der erste Bug wird von einem Menschen gefunden
Beim Herumstochern in der Preview: zwei seltsame Mitglieder namens „x", die Salden tragen, und keine Möglichkeit, sie zu löschen. Gemeldet so, wie ein Mensch Dinge tatsächlich meldet:
I see some strange users x which have a non zero balance but I don't see any expenses associated to them. And I can't delete them.
Die Diagnose ist eine Geschichte über automatisiertes QA: Während der Runtime-Verifikation hatte der Headless-Browser des Agenten in das echte Mitglied-hinzufügen-Formular getippt, und die Test-Mitglieder blieben hängen. Sie zu löschen brachte dann eine echte Design-Lücke ans Licht — Mitglieder, auf die Ausgaben-Splits verweisen, waren durch Foreign Keys geschützt, und das UI hatte darauf keine Antwort.
Was neun Minuten später zurückkam, war besser als ein bloßes Freischalten des Löschens: ein Re-Split-Design — beim Entfernen eines Mitglieds werden dessen Anteile auf die verbleibenden Teilnehmer umverteilt — plus ein Regressionstest für genau den Fall, den die bestehende Suite nicht abdeckte (die eigene Beobachtung des Agenten, aus seiner Narration). Einundzwanzig Tests grün, committet.
Das ist die Iterationsschleife, um die diese Plattform herum gebaut ist: Der Bug kommt als Satz an, der Fix kommt als verifizierter Commit an, und die Person auf der Piste hat nie einen Stacktrace gesehen.
23:00 — was eine fertige Wochenend-App kostet
Die Rechnung des Abends, aus den Metering-Tabellen:
- Build: ~4,8 Mio. Tokens durch das Coding-Modell über zwei Runs und die Fix-Iteration — rund 3,50 $ rohe Modellkosten für eine vollständige, getestete, geseedete Full-Stack-Anwendung.
- Idle: 148 Sekunden nach dem letzten Keepalive fror die Plattform den Container der App am cgroup ein — genau diese App, aus genau dieser Geschichte, gab an ihrem ersten ruhigen Abend 201 MB RAM an den Swap frei. Ihr Datenbank-Compute skalierte separat auf null. Eine untätige Wochenend-Idee kostet standardmäßig praktisch nichts, auf unbestimmte Zeit.
Die Tabelle starb um 18:42. Bis zum Abendessen gab es eine App mit verifizierter Mathematik, einem eigenen Datenbank-Branch, einer Testsuite und null Idle-Kosten — und niemand auf dem Trip muss wissen, was ein LSN ist.
Was die Preview noch nicht verspricht
Alles oben ist immer noch die Preview eines einzelnen Nutzers — und eine Preview verspricht so gut wie nichts. Der interessante Teil im Leben dieser App beginnt, wenn sieben andere Leute die URL bekommen: ein Produktions-Deploy, der die Daten-Timeline forkt, echte Ausgaben von echten Freunden, die der nächste Deploy nicht anfassen darf, eine riskante Migration und — wenn es schiefgeht — ein Rollback mit expliziten Regeln darüber, was er löschen darf.
Das ist Teil zwei der Geschichte dieser App. Die Mechanismen sind in Akt 2 bereits beschrieben — diese App hat sie nur noch nicht durchlebt. Bis Sonntag wird sie es.